|
I recently join Roblox as a Principal AI Scientist, and we are working on 3D foundation models. Send me an email if you want to work with us! I was a Research Lead at Playground. We worked on pixel-foundation model and we open-source and developed the SoTA image generative models, playground-v2, v2.5 and v3. Check out the publication for more details. I was a Senior Research Scientist at NVIDIA Toronto AI Lab in Toronto, where I work on computer vision, computer graphics, generative models and machine learning. At NVIDIA, I work closely with Sanja Fidler and Antonio Torralba. Several of our works have been integrated into NVIDIA products like Omniverse and Clara. I graduated from University of Toronto and I recieved MICCAI Young Scientist Awards runner-up. Email / Google Scholar / Twitter / LinkedIn / Github |

|
|
|
|
I'm interested in computer vision, computer graphics, generative models and machine learning. Much of my research is about exploiting generative models for various computer vision tasks, such as semantic segmentation, image editing, and representation learning. |

|
3D Foundation Team., Arxiv, 2025 blog / video / arXiv / github / huggingface We open-source our text-to-3D foundation model - Cube3D and arxiv a position paper of our long-term vision on 3D Intelligence in Roblox. |

|
Bingchen Liu, Ehsan Akhgari, Alexander Visheratin, Aleks Kamko, Linmiao Xu, Shivam Shrirao, Joao Souza, Suhail Doshi, Daiqing Li Arxiv, 2024 blog / video / arXiv We propose a new text-to-image model architecture that deep-fusion large language models(Llama3) to improve text-to-image alignment. Our model achieves state-of-the-art performance in terms of text generation and text-image consistency, better than Flux and Ideogram. |

|
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, Suhail Doshi, Arxiv, 2024 blog / huggingface / video / arXiv We share three insights to enhance aesthetic quality in text-to-image generation. Our new model achieves better aesthetic quality than Midjourney 5.2 and beats SDXL with a large margin in all multi-aspect ratios conditions. |
|
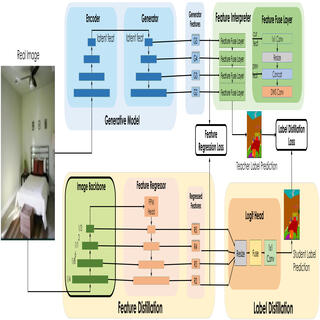
Daiqing Li*, Huan Ling*, Amlan Kar, David Acuna, Seung Wook Kim, Karsten Kreis, Antonio Torralba, Sanja Fidler, ICCV, 2023 project page / video / arXiv We propose a new pre-training framework by distilling knowledge from generative models onto commonly-use image backbones, and show generative models, as a promising approach to representation learning on large, diverse datasets without requiring manual annotation. |
|
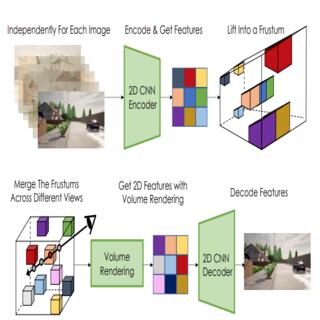
Seung Wook Kim, Bradley Brown, Kangxue Yin, Karsten Kreis, Katja Schwarz, Daiqing Li, Robin Rombach, Antonio Torralba, Sanja Fidler, CVPR, 2023 project page / video / arXiv We use lift-splat-shoot like representation to encode driving scene and nerf like representation to decode scenes with view controls. We then learn a hierarchical LDM on the latent representation for driving scene generations. |
|
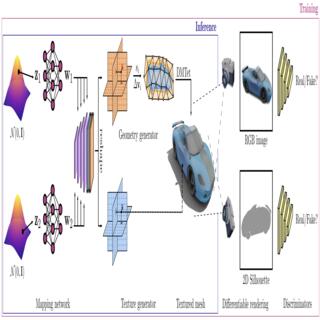
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, Sanja Fidler, NeurIPS, 2022 (Spotlight Presentation) project page / video / arXiv We develop a 3D generative model to generate meshes with textures, bridging the success in the differentiable surface modeling, differentiable rendering and 2D GANs. |
|
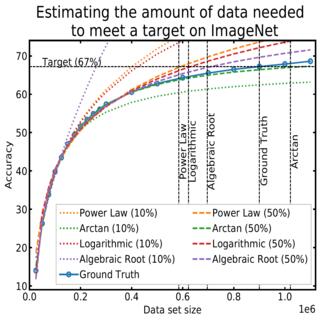
Rafid Mahmood, James Lucas, David Acuna, Daiqing Li, Jonah Philion, Jose M. Alvarez, Zhiding Yu, Sanja Fidler, Marc T. Law, CVPR, 2022 project page / video / arXiv We use a family of functions that generalize the power-law to allow for better estimation of data requirements under limited budgets. |
|
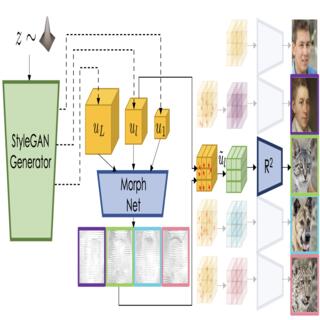
Seung Wook Kim, Karsten Kreis, Daiqing Li, Antonio Torralba, Sanja Fidler, CVPR, 2022 (Oral Presentation) project page / video / arXiv We use GAN to model multi-domain objects with shared attributes, and use morph net to model geometry differences. We show its application in segmentation transfer and image editting tasks. |

|
Daiqing Li, Huan Ling, Seung Wook Kim, Karsten Kreis, Adela Barriuso, Sanja Fidler, Antonio Torralba CVPR, 2022 project page / video / arXiv We extend DatasetGAN to large-scale dataset ImageNet with as few as 5 annotations per ImageNet category. |
|
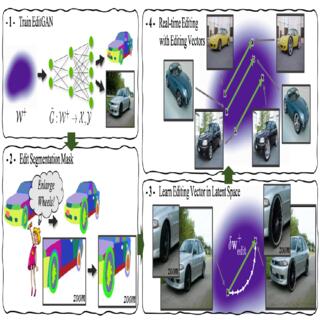
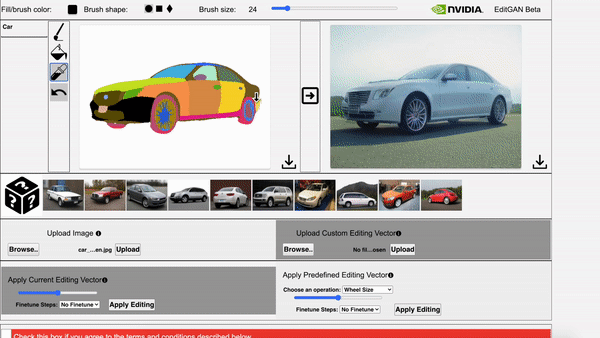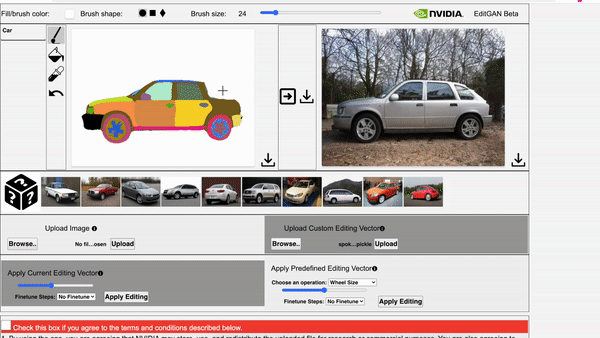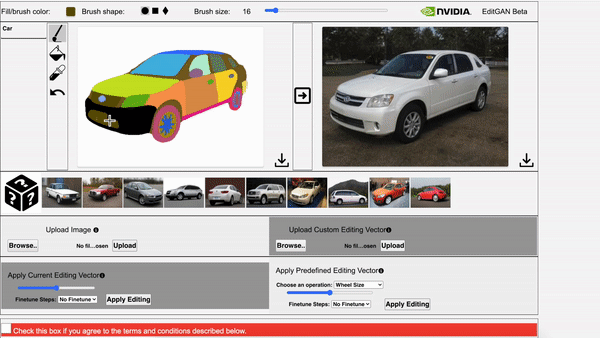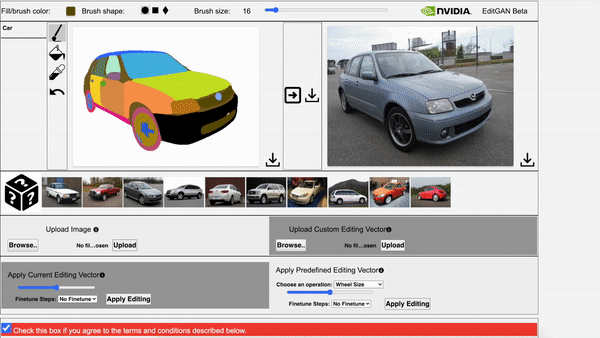
Huan Ling, Karsten Kreis, Daiqing Li, Seung Wook Kim, Antonio Torralba, Sanja Fidler NeurIPS, 2021 project page / video / arXiv We use GAN to model joint distribution of images and semantic labels, and use it for semantic aware image editing. |

|
Daiqing Li, Junlin Yang, Karsten Kreis, Antonio Torralba, Sanja Fidler CVPR, 2021 project page / video / arXiv We use generative models to model joint distribution of images and semantic labels, and use it for semi-supervised learning and out-of-domain generalization. |
|
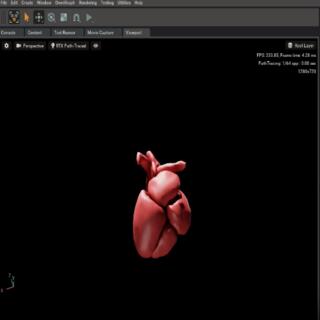
Daiqing Li, Amlan Kar, Nishant Ravikumar, Alejandro F Frangi, Sanja Fidler MICCAI, 2020 (Young Scientist Awards (YSA) Runner-up) project page / video / arXiv We introduce a physics-driven generative approach that consists of two learnable neural modules: 1) a module that synthesizes 3D cardiac shapes along with their materials, and 2) a CT simulator that renders these into realistic 3D CT Volumes, with annotations. |
|
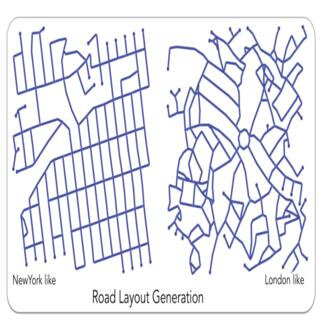
Hang Chu, Daiqing Li, David Acuna, Amlan Kar, Maria Shugrina, Xinkai Wei, Ming-Yu Liu, Antonio Torralba, Sanja Fidler ICCV, 2019 (Oral Presentation) project page / video / arXiv We propose Neural Turtle Graphics (NTG) to model spatial graphs, demostrate application in city road layouts generation. |

|
Hang Chu, Daiqing Li, Sanja Fidler CVPR, 2018 project page / video / arXiv We use an RNN encoder-decoder that exploits the movement of facial muscles, as well as the verbal conversation. |
{kind=link}
|
|
| Program Committee: AAAI 2025. |
| Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR |
|
|
|
Jihyeon Je (PhD, CS Stanford) Working on
3D Object Open-Vocabulary Segmentation. |
|
|
|
Template from source code. |